|
|
2 years ago | |
|---|---|---|
| Padliography.egg-info | ||
| static | 2 years ago | |
| templates | 2 years ago | |
| .gitignore | ||
| README.md | 2 years ago | |
| cover.jpg | ||
| format.ipynb | ||
| lifecycle.jpg | ||
| pad-bis.py | 2 years ago | |
| setup.py | ||
{kind=link}
{kind=link}
README.md
Padliography bis

The Padliography is a tool to keep track of our pads. It is built to interact with the MediaWiki API, and it uses XPUB & Lens-Based Wiki's pages as archive.
Features:
- Multiple archives
- Custom categories
- Filter by categories
- Table Sorting
- Create new pad
- Interact with the wiki
Quick Start
The Padliography homepage loads by default the XPUB2 archive. Just above the pads list it is indicated from where the pads are being fetched, and it is possible to change source by inserting the title of the page in which the other archive is.
To create a brand new archive click on Init a new padliography and insert a title and a short description to put in the wiki.
Watch out: This action will create a new blank page, so check that there is not already something with the same title in the wiki, or it will be overwritten. Thanks to the wiki's history, it is possible to recover overwritten contents, so the contents are not in total danger.
Use the Add new pad form to insert a pad in the archive. The required information are a title, the URL of the document, a short description, a date and some categories. The categories are custom, and are useful to organize pads in themes or context.
The Filter Categories section loads all the categories from the current archive and uses it to filter the list of pads.
The list of pads is sortable. Click on the headers to order the pad, click twice to invert the order.
At the moment this Padliography instance runs on the Soupboat. If you are using it a lot or with a lot of pads, consider to install a new instance on a different environment, in order not to put a strain on the small Raspberry. It should be fine anyway.
How does it work
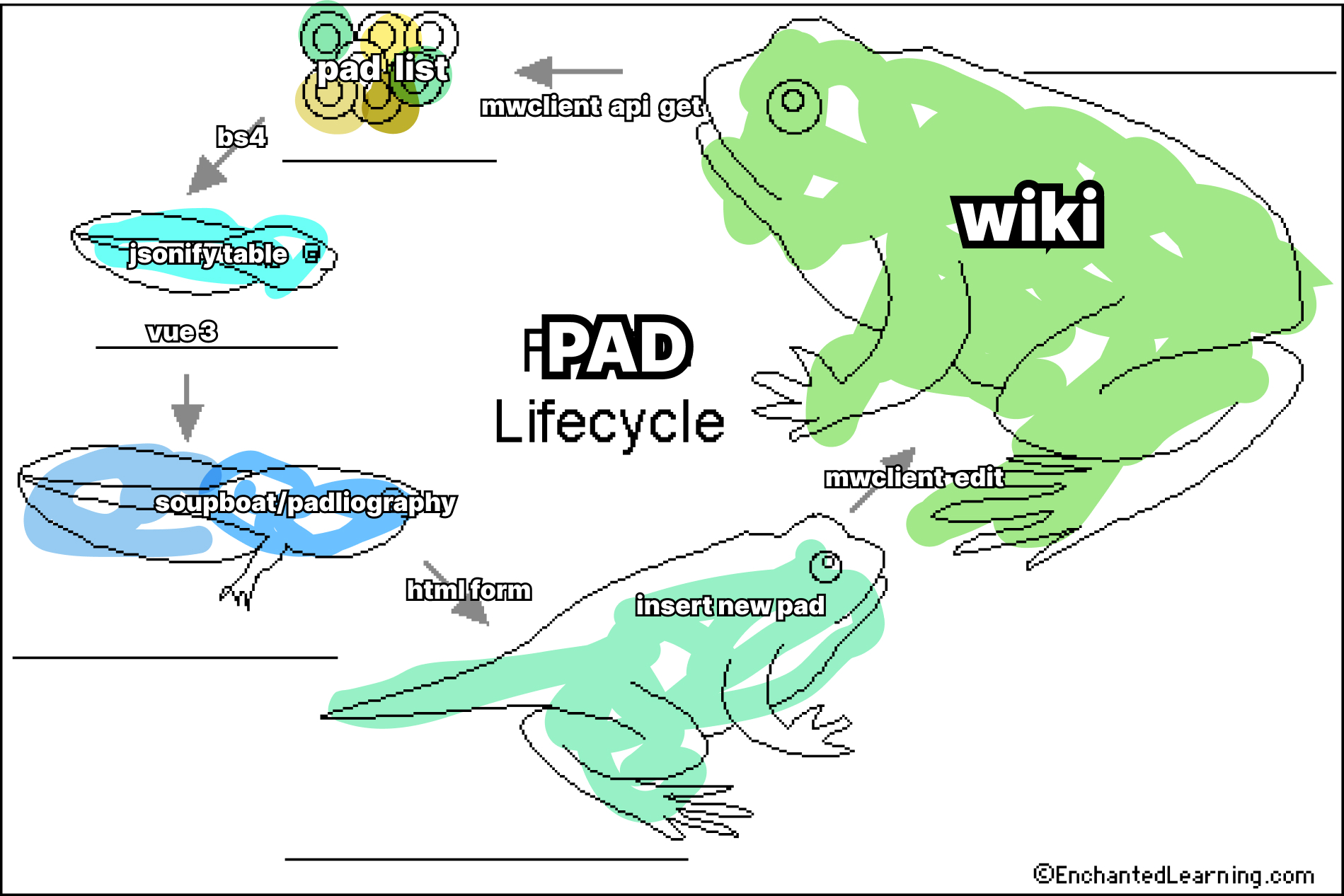
To have an overview over the lifecycle of the Padliography let's start from the wiki.
The pads are stored in a page with a minimal template, such as the title, a short description and a section named Padliography with the archive. Here they are organized in a table that has the CSS class padliography.
Through the MediaWiki API we can request the contents of this page from somewhere else. This somewhere else is a small Raspberry Pi called Soupboat and installed on the 4th floor of the WdKA.
The Soupboat is a small server, and it runs a Flask application that interacts with the wiki using the mwclient python library.
When a user enters the homepage of the padliography, the Flask application returns a Vue3 app and through that requests to the wiki API the list of pads.
The response from the MediaWiki API is parsed on the server using BeautifulSoup, that tries to find the padliography table with some CSS selectors and then builds a list of pads organized by the properties of the table's headers. The list of table is sent to the Vue app as JSON message, and used to compile a fancy sortable table and filtering system.
When a user interacts with the form to add a new pad the process is the same, but in the opposite direction: first the Vue app sends the data to the Flask application that in turns tries to add it in the archive wiki page.
Development
Local setup
To install the Padliography somewhere else start by cloning this repo.
git clone https://git.xpub.nl/kamo/pad-bis.git
Then move to the cloned repository folder and create a python virtual environment.
cd pad-bis
python3 -m venv venv
Activate the virtual environment
# on unix
source venv/bin/activate
# on windows
venv\Scripts\activate
and then install the requirements with pip. The . here refers to the current working directory, where the setup.py file can be found. There are specified all the packages the application needs.
pip install -e .
Once the installation is completed, launch the application and open it on the default port .
python pad-bis.py
If you open localhost:5000 on your browser, it will return the padliography stuck in the loading process. This is why before interacting with the MediaWiki API we need to specify the credential for a user to log into the wiki. On your local version you can use your own credentials, but if you plan to put this padliography online it's better to use a dedicated user, aka a bot.
Remember not to commit your credentials on git, or they will be rendered public! Instead create and .env file, that will not be uploaded on git as specified in the .gitignore file.
Create an .env file in your working directory with the following properties:
MW_BOT= your username
MW_KEY= your password
At this step you are up and running, the padliography should be able to fetch the pad from the wiki etc.
Deployment ?? Production ??
There are so many technical terms I'm not confortable just using, so I need to negotiate a glossary.
Sometimes to find alternatives: like what happened with the naming of default branch in platforms such as GitHub, that switched from master to main in order to stop using terms related to slavery.
Sometimes to retreace genealogies, that is: to offer other contexts for a word to refer to. A redemption arc for cursed words. No clue how to do it though, a way could be to use them critically, stumbling upon them, connnecting with different images. So here some attempts.
Deployment in software and web application means to push changes from a development environment to a production one. To move and install the code from your computer to a server, for example.
When writing a piece of documentation together with my friend Chae, she reacted puzzled to my generic use of this very specific word? I reacted puzzled to this puzzlessness, and went searching for the real-world meaning of a term imported and naturalized in the technical jargon.
Deployment is a military term, that refers to moving troops and army around on the battlefield. The spatiality of this gesture, going from home to the warzone, or from a target to another, suggests a form of detachment from its consequences, rendering them far away. Do we feel less responsible for what's happening so far? Perhaps the contrary. When something goes wrong on a distant server, what we feel is the helplessness of something being out of reach.
It's not surprising that technologies developed within army still talk a soldiers' language. But being so un-surprising, words and the worlds they carry along sneak into our worldviews, becoming normal, natural, invisible. Becoming just the way the world is, justifying and reinforcing the separation between user and developer, server and served, etc.
Looking at etymology, deploy feels close to display. They share roots and gestures of making something visible and public, not to seclude it far away, but to make it accessible.
Let's see.
NGINX Configuration
To deploy the padliography on a server and make it accessible from a web browser, it's necessary to configure a way to make the communication between the application and the world possible.
In a server a lot of things are happening at the same time. When unfolding an application there it's important to reserve it a dedicated channel to talk with the outside.
There are various way to organize this communicational tangle: one of them is to use a reverse proxy. This system acts as a thin layer that intercept the messages that a server receives, delivering them to the appropriate application.
In order to make it work, every app that need to exchange data with the outside listen to a so called port, that is something like an address in the internal network of the server.
A reverse proxy listen to the external requests that come from the web, such as someone visiting the url https://hub.xpub.nl/soupboat/padliography, checks in its list of location and ports and finally finds out that indeed, requests to /soupboat/padliography are actually directed towards the port number 3000.
In this particular case we are using NGNIX. If you happen to use it as well, adding a location for the padliography is straight forward.
The following instruction assumes you have cloned the padliography in the /var/www/pad-bis/ directory. If you choose to deploy it somewhere else be sure to change the alias path accordingly in the following configurations.
Open the default configuration file:
sudo nano /etc/nginx/sites-available/default
and inside the server section add a new location:
server {
#note that your configurations may differ!
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html
# ADD FROM HERE
location ^~ /padliography/static/ {
alias /var/www/pad-bis/static/;
autoindex on;
}
location ^~ /padliography/ {
proxy_pass http://localhost:3147/soupboat/padliography/;
include proxy_params;
}# TO HERE
}
In this configuration there are two locations: one for the static files such as images, css and js documents, and one with the proxy_pass that points at the internal port where the application is listening for updates.
Another important aspect to take into account is the port where to redirect the user's request. In this case is 3147, but any available port is good. This is the same port you define in the .env file!
As previously said in a server a lot of things are going on at the same time, so in order no to make a mess with free and occupied ports sometimes is nice to adopt a strategy that helps developers choose a good one. In the situation of the Soupboat, we keep an incremental comment in the config file that suggest what port to use next.
Something as simple as
# ATTENTION: use port 3159 for the next project!!!! ;))
Everyone updating the configurations with a new project also updates the message for the next one. It's a simple way but it works! It's also a nice way of leaving messages for future developers coming to the NGINX config file.
Once you added your entry, you want to check that everything looks good and there are no typo or other errors in the configurations.
To do so run the test command
sudo nginx -t
And if the output says that things are ok you can relax and reload the server to make the changes effective.
sudo systemctl reload nginx
If the test command prints some errors check them out: usually they are clear and comprehensible. Probably you forgot a semi-column or used a dupplicated location. Fix it and then try to test again! It's dangerous to reload the server without checking it first, because this can break things and make the server inaccessible if you are accessing from a web interface such as jupyter lab.
TODO: .env and config doc
License
This Padliography was distilled with the help and within the context of XPUB, 2022.
Copyleft with a difference: This is a collective work, you are invited to copy, distribute, and modify it under the terms of the CC4r.