Contents
Feedback from initial bootleg library sessions: introduction[edit]
Some feedback collected during introductory sessions:
Languages[edit]
| user feedback | decision |
|---|---|
| 1. Descriptions of non-English texts: what is the best protocol? 2. Finding texts in non-English languages - possibly hard to find digital files, easier to find in print? |
1. They should be in the language of the text, with an English translation if possible 2. Digitise printed texts using the bookscanner |
Categorising[edit]
| user feedback | decision |
|---|---|
| 1. There is a lot of redundancy on the "categories" page. Categories are defined by tags - which are written subjectively, or downloaded from existing data on the uploaded books. There should be a distinction between categorising texts, and tagging them. 2. Tags are case-sensitive, leading to multiple entries of the same tag (e.g. Media Theory vs Media theory vs media theory) |
1. Create a series of general categories, and then tags can exist as sub-categories. Further to this, can tags also be used dynamically? E.g. being able to highlight more popular tags? Tagging people? 2. Force all tags to be in lowercase |
Cataloguing[edit]
| user feedback | decision |
|---|---|
| 1. We noticed that if an article is uploaded from JSTOR, the book automatically takes the JSTOR logo as the cover. Is this because it is watermarked on the first page of the PDF? |
1. Could watermarking be a way to make covers of future uploaded PDFs? |
Interface[edit]
| user feedback | decision |
|---|---|
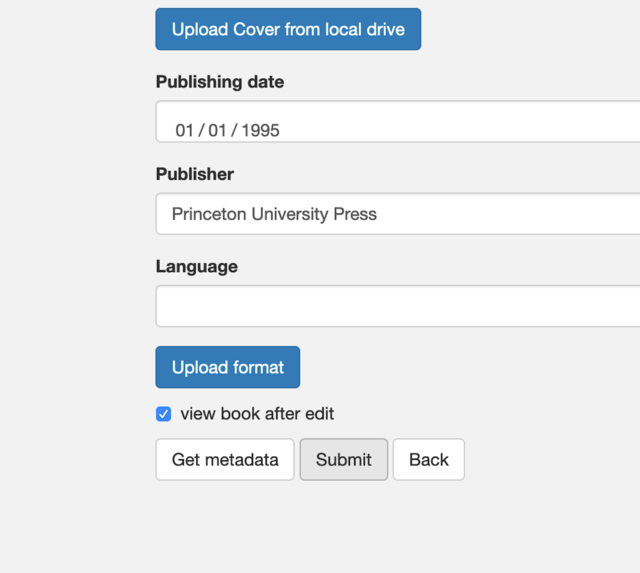
| 1. Upload cover from local drive - currently only accepts jpegs, and the field remains empty after you choose a jpeg to upload 2. "Submit" button vs "Upload format" button - a bit confusing because of placement, similarity of meaning between "submit" and "upload" |
1. Allow png to be accepted, and make it clearer within the interface that the cover image has been uploaded (perhaps with a thumbnail of it?) 2. Create a clear distinction between uploading a new format of the same text, and submitting metadata, e.g. "upload", and "add new format" |
{kind=link}