BASH script

A BASH script is a series of commands stored in a text file. It contains commands that one would use in the command-line.
We used BASH scripts to automatically upload batches of files including metadata to the Wiki.
pagename = f'{dirname}-{_file}'
print_colormsg(pagename, level='ok')
page = site.pages[_file]
if page.exists:
url = page.imageinfo['descriptionurl']
print_colormsg( f'Already exists in {url} Will NOT be uploaded', level='warning')
else:
img_smw_prop_val = smw_propval_template.render(
title=args.title,
date=args.date,
part=n + 1,
partof=len(lsimgs),
creator=(', ').join(args.creator[1:]),
organization=(', ').join(args.org[1:]),
format=(', ').join(args.format[1:]),
event=(', ').join(args.event[1:]),
topic=(', ').join(args.topic[1:]),
language=(', ').join(args.language[1:])
)
Dark Web
The Dark Web is a portion of the Internet that one cannot reach by the use of regular search engines. Users need specific software, configurations, or authorization to access to be able to use it. This shelter of anonymity is of a great importance while dealing with censorship and privacy concerns, and because of that the Dark Web is also oftenly perceived as a haven for criminal activities. Tor browser is probably the most used tool to access the dark web.
The Dark Web offers the protective layers that make sure the location of the servers and the identity of the users is secure in the case of possible attempts of persecution of any kind.
Tor Browser

Using the Tor Browser helps prevent others from tracking your browsing behavior and user details like location. It is provided by the Tor Project, a non-profit organization. It works by routing all your internet traffic trough random nodes, listed in the Tor network and thus rendering the origin of it unrecognizable.
It is probably the most famous tool used to access the Dark Web.
everywhere, always, online
somewhere, sometimes, offline
nowhere, never, online
Image Magick

Image Magick is a free command-line tool. It comes with extensive functions to edit and convert images.
We used Image Magic to convert multipage PDFs into individual JPGs to upload to the Wiki.
Pandoc

Pandoc is a free command-line tool used to convert one markup format into a different one.
We used Pandoc in the process of converting documents written in markdown into HTML.
Tesseract

Tesseract is a free "optical character recognition" (OCR) engine, and supposedly was the first one of its kind. It recognizes text within images and outputs this textual content in either a text file or a PDF in which the text is selectable and searchable.
Tesseract is essential to provide a comprehensive overview when working with a big batch of scanned documents. The quality of the results depends very much on the quality of the documents and thus can result in the need for large-scale revisions. More concretely - not all images that contain text seem to be readable by Tesseract. Some images might be damaged (faded ink, strange font, etc.), therefore the recognition does not afford precise results. This is when humans come back into play, to edit and correct the inaccuracies, to proofread the machine.
MediaWiki

MediaWiki, the basis for Wikipedia and most other MediaWiki websites, is a free and open-source "collaboration and documentation" platform engine. Wiki markup is the language used to write content on a wiki website.
MediaWik served us as a platform that allows many users to handle large amounts of image files and metadata collectively. It features helpful tools to do so, such as page forms, semantic queries and an API.
* List item
** Sublist item 1
** Sublist item 2
Raspberry Pi
Raspberry Pi is a series of small computers with internal RAM & CPU/GPU and several connectors, like USB or Ethernet. They are being used by a big and diverse community, in education or for all kinds of prototyping projects.
We used them as a low cost web server to store our websites. As a security measure, three similar servers in different, secret locations provide continuous access to the material, serving as alternative hosts, should one of them be taken down or fail. The basic code structure is being created with Python.
Markdown

Markdown is a markup language.
Markup languages are used to structure the linguistic syntax of a chosen system in a more user-friendly way. These languages are supposed to be easier to use than the actual code, as they are to be read by humans. What is written can easily be converted into the syntax of other languages.
Markdown has been originally developed to simplify writing HTML, but has ever since changed its role and now it provides conversions into different formats.
We used Markdown while creating the annotated readers (SWARM 1,2,3) in order to convert plain text into html.
| ------------- |:-------------:| -----:|
| 3 is | right-aligned | $1600 |
| 2 is | centered | $12 |
| computers | are neat | $1 |
HTML, CSS, JS
Hypertext Markup language (HTML) is what the basic building blocks of the web are made of. This language defines and categorizes the content of a website and guides the user, e.g. from one page to another with the use of the so called hyperlinks.
Cascading Style Sheet (CSS) is the visual facade, the makeup that is put on top of the HTML content. It refers to the categories assigned before. It is responsible for how a website looks like and also for basic interactions & animations.
Java Script (JS) is the busy crane-worker that is still around, even after the building is already finished, to rearrange building blocks. Java Script controls interactions, animations, the loading and transformation of content.
These languages can either be written all in one document or in separate ones, linked to one another.
We used HTML, CSS and Java Script to create this website. We used CSS and Java Script to further edit the HTML created with query2HTML.
<style>h1 {color: white; text-align: center;}</style>
<script>document.getElementById("header").innerHTML = "Anonymous publishing";</script>
Web2Print

Web2Print is a method, that uses websites as a basis from which print layouts are created. When using this online workflow contents are open to a number of contributors, flexible and easy to change throughout the process.
We used Web2Print to enable the printing of the website you're looking at, as well as for the creation of the annotated readers (SWARM) in their physical form.
Page forms (MediaWiki)

Page forms is an extension that provides a MediaWiki instance with templates to create pages, edit pages and add query data to them.
We used these forms to implement the same categories for each document and assign them their collected properties.
|Title=documenttitle
|Date=1987/11/01
|Part=
|Partof=5
|Creator=Organization1 (Org1), Organization2 (Org2), Organization3 (Org3),
|Format=Paper, Manual
|Event=
|Topic=Political Ideologies, Arts and Culture, International Affairs, Economics, Resistance Tactics
|Language=English
}}
=OCR=
Original file name: filename.pdf
Semantic queries
While lexical search returns literal matches to a search request, semantic search "understands" the query. When compiling the search results, this search procedure relies on previously entered, definitive, metadata information and thus usually returns more accurate results. Multiple requests can be combined to create more complex queries. There are two different factors to the queries: Which pages the search is based on and which information is obtained from them. WikiMedia uses a simple semantic language "semantic MediaWiki" for this.
We used it to selectively query the previously entered content using meta data.
[[Located in::Germany]]
|?Population
|?Area#km² = Size in km²
API

An API (Application Programming Interface) is an interface that enables external programs or systems to communicate with the software. The API defines how to access and how to define requests. Some APIs are created specifically for certain programs, others follow industry standards.
We used MediaWiki's API to organize and bundle a large amount of material and later in the process also to export the search queries from the Wiki user interface and then, using query2html, converted them to HTML.
Python script

Python is a highly abstract (high-level) programming language in which logical and clearly structured codes for projects of various sizes have been written since 1991. It is equipped/comes with a significant amount of libraries that simplify complex tasks.
We used the Python library Mwclient to interface with the MediaWiki API in order to extract the results of semantic queries.
Static website

A static website, the opposite of dynamic websites, is a website with unchanging content, which is mostly written in HTML and outputs the exact same content to each user. Benefits of this model are the lack of dependencies and increased security and performance.
A static website was used to publish the archive.
query2HTML
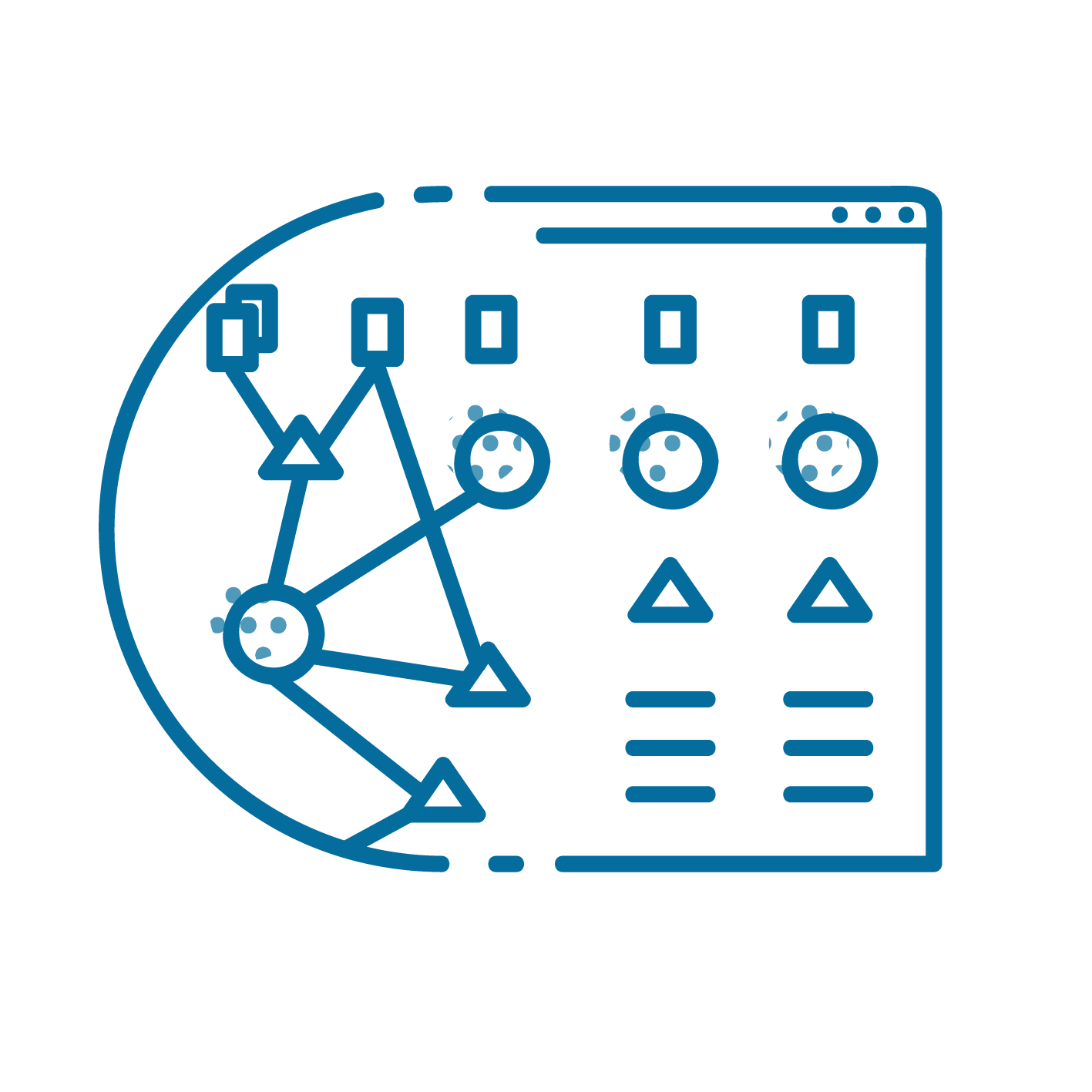
Using the MediaWiki API, Python and Pandoc we converted the results of semantic queries to a static website.
GIT

GIT is a version-based online data storage service that is used mostly to collectively work on code. This collaborative working environment retains all versions created, it is non-destructive. It also features the option of dividing a project into different versions, so called branches, which can be processed separately, and merged again afterwards.
Ether2HTML

An Etherpad document can be used to collectively work on HTML, CSS and Javascript code, while still seeing a real time preview, using CURL.
We used this method while creating the website you're looking at.
Curl

Curl is a command line tool, that automatically downloads content from a given URL and stores it in a file on your machine.
We used this tool as part of the Ether2HTML method.
Etherpad

Etherpad is a open source online text editor that allows an unlimited number of contributors to collaborively write in the same virtual space in real time. This tool was used in all parts of the process to collectively take notes, write and organize content, collect, communicate and work on code, using the Ether2HTML method.
Code of conduct

We created a code of conduct to make sure that we were on the same page about the fundamentals of our regular interactions as a group. It served as a reference on how to approach each other and helped prevent avoidable unconstructive conflict.
- Listen, don’t interrupt.
- Listen actively - Show that you’ve understood.
- If you don’t agree, you can still accept others opinions.
- When negotiating, be convivial (be nice!).
- Ask what is needed before you give.
- If personal issues arise, try to address/resolve - if not: park it for the sake of the project.
- When you don’t understand, ask for help (be humble).
- Be aware of the space you take. (Check temperature - silence is OKAY!)
- Before making a decision, check with others (might be an unhappy average).
- Speak for yourself and your own experience (see links: nonviolent communication)
- Use „AND“ instead of „BUT“ and „HOWEVER“.
- These rules can be modified by consensus.
Obtaining background knowledge

To develop an understanding of a complex topic, basic research - on/offline - is the first necessary step to take. Talking about the facts as a group and/or collectively reading texts on the topic can help in the process. If possible, the best way to develop a deeper understanding is to get in touch with experts and/or witnesses. In the best case, to conduct an interview or even organize a meeting as a group or a workshop on the topic. Also taking as many different points of view, even if you don’t agree with them, is an imperative to create a differentiated opinion on a complex matter.
Getting a first impression
When having first contact with the material that will constitute your work, getting a first quick overview and comprehending the scale of it, can influence the development of your process drastically. The reason for this is that, especially in time-limited projects, the first impressions significantly affect or even determine the creative and conceptual design that you decide for. Therefore, the fist contact with the material should be made with caution and calmness.
In order to get a good overview of the archival material, when we first encountered it, we divided the documents, skimmed them and created a polyptych summary that also served as a basis for a collective discussion. Beforehand, we had trained our understanding of text in order to be able to process the material effectively.
Reading Exercises

Several different reading exercises helped us to enhance our text comprehension and prepare for the mental processing of large amounts of content.
Requires two participants with two different texts, of whom one (Person 1) starts reading their text out loud. Person 2 skims their text until they find an idea in their text that relates in some way to an idea, a thought that is being read out loud by Person 1. They both mark this adjacency and briefly discuss the interconnections between the two different ideas from both texts. Then they switch roles. Person 2 reads their text out loud, beginning at the last marked adjacency. They repeat this process as long as they want. This exercise is meant to create an intertextual environment in which both readers are challenged to highten their perception and their awareness of both texts, seemlingly unconnected at first. With the use of their imagination they find places where both texts overlap.
Reading Exercise 2: Slow reading
A group reads one text together, whereas each person reads only one sentence out loud, rotating clockwise. At times, one person can also read longer sections of the text, depending on its complexity. After the word is given to the next person in the rotation, the group collectively talks about what they understood from the sentence that was read and discusses their diverse takes on the meaning. The purpose of this exercise is to understand the text collectively and to enhance understanding of its content by helping each other think and deliberate, articulate. Slow reading is a training for an kind of a reading practice, where the reader challenges themselves into better understanding each building block of the meaning that the text is transmitting.
Reading Exercise 3: Blackbox
This exercise requires four participants. The "two channels" sit on the left and the right side of the speaker. They simultaneously whisper into the speakers' ears, reading out loud - a different text each. The speaker is the one in the hot seat. She/he listens to the whispered input and quickly and without thinking too much continuously communicates the information gathered from the two channels, interprets and invents an individual real-time speaking method. The listener is facing the speaker, he/she is the one that is taking notes of everything that the speaker utters. They stay in this constellation for the duration of three minutes, then rotate the roles around. The exercise finishes when everybody got to be in all of the four positions. Afterwards, they have a conversation on how they perceived the different roles. One person is always listening to the other three speaking, and notes down everything that they say.
Reading Exercise 4: Composite highlights
Two groups read two different texts that can be related. Using a pen or marker each participant highlights the most relevant parts of the text for them. By this, they are creating a brief subjective summary. Afterwards, the whole group combines all of their individual emphasis, to create one common summary. After that, each group has to agree on a form of a presentation in which all the participants can be heard. They present their understanding of the text to the other group. There can also be more groups than two, the division depends on the number of people involved in the exercise.
Polyptych Summary

Traditionally a Polyptych is a painting, split into sections. In this case we used the idea of a polyptych as an exercise that enables us to get a first impression of the archive material.
Categorizing the material

To be able to navigate the material, you have to make connections in between the documents, get an overview of all of the existing data and from this develop a structure for the archive. We chose to categorize the material with content and format related categories.
To start, each person skimmed a portion of the archive they were responsible for (as decided when dividing the work). During this process, properties that we considered relevant and/or seemed to be recurring throughout the material were collected for each document. Further, all categories and properties were gathered, discussed and reduced to the necessary. The thereby generated set of categories and properties was then applied to the documents by re-skimming them. The categories and properties were later used for the upload of the material to MediaWiki using page forms and were structured there.
- Paper
- Interdisciplinary Doctoral Fellowship
- Marxism
- Capitalism, Socialism, Class structure
- Readings, Literature
- Soviet Union
- Economy
- Peoples Republic of China
- Socialist Republic of Vietnam
- Reforms
- Revolution
- Revolutionary armed struggle, revolutionary army
- Street fighting
Annotated reader (SWARM 1,2 & 3)

Using the slow reading method we have read several texts as a group. We have collected annotations, additional information and imagery on an Etherpad. Afterwards, we have collectively revised the collected content, added a glossary, styled it with CSS - designed a cover and designed the overall appearance of it. We have converted it to a print layout using the Ether2HTML and Web2Print methods. Afterwards, we have printed out this material as booklets, which we have named: SWARM 1, 2 & 3.
Technical limitations

Under certain conditions it may be necessary to publish content without leaving a trace of identity behind. To protect the contributors and server locations also means working with some technical limitations. At our project, this boiled down to facing reduced bandwidth speed when accessing websites, hosted in the Dark web through the Tor Browser, and also because of the necessity of implementing a static website.
It makes no sense to try and work against these restrictions, but rather to accept and find ways to work within the limitations. A clearly defined field of work can also speed up and enrich the process.
Division of labor

At several different moments during the process we have divided upcoming tasks to individuals or groups. Right after the first contact with the archive material, we have split it into ten equal parts. Each individual had to deal with their part, while obeying the collective structure of categories and properties that we defined collectively. Later on in the process, we have split the class of ten people into two sub-groups: one caring for the actual archive, while the other worked on the public website (that you are currently lurking at) and a printed publication. Within these sub-groups, specific tasks were further divided between the individuals. The crucial importance for this approach are regular live meetings with the entire team, where catching-up and exchange of information happens. Of a big significance are also platforms on which we document progress. Do eveything you can to keep in contact with the work of other people.
Collecting references

When developing the structure, form and function of the publication, it was essential to collect references. For inspiration, but also to communicate complex ideas in a team. Very helpful were lectures and discussions with Maydayroom, The Warp and Weft of Memory and OpenSourcePublishing.
Thread Model
A threat/thread model is a set of rules that lists and evaluates all the resources and contents of a project before starting to embark on the projects' journey. A threat model sets clear limits that must be respected when working together.
During the process we have implemented a thread model to prevent the unwanted publication and communication of sensitive information.
COVID 19

In the midst of the process of dealing with our project, the global society was overwhelmed by the outbreak of the COVID 19 pandemic. Several drastic limitations followed. The most severe impact this situation has had on our project, was of course the closure of all educational facilities and the need for social distancing, to which we complied. This of course resulted in before unknown limitations to our collective process. Due to these circumstances, our launch was provisionally canceled and we were given an extra of two weeks to be able to slow down the process and finish our project.